Horovod를 활용하여 Tensorflow에서 Multi GPU로 학습하기 (BERT Distributed Training 해보기)
by y-rok
이번 포스트에서는 Horovod란 무엇이고 Multi-GPU로 Deep Learning 모델을 학습하는 Distributed Training에 대해 소개하고자 합니다. 이를 위해, Horovod에서 제공하는 Benchmark 소스를 활용하여 가지고 있는 서버 환경에서의 Distributed Training 성능 평가와 Google에서 공개한 BERT Code를 Horovod를 활용하여 Distributed Training 할 수 있도록 구현 해보고자 합니다. (BERT code는 TPU 환경에서만 Distributed Training을 지원합니다.)
다음의 순서로 설명하겠습니다.
- Horovod 란?
- Horovod의 Distributed Training 동작 방식
- 서버 환경의 Distributed Training 성능 측정하기
- BERT Fine Tuning을 Distributed Training으로 구현해보기
Horovod 란?
Horovod란 Tensorflow, Keras, Pytorch, MXNet에서의 Multi-GPU를 활용한 Distributed Training을 지원하는 Framework입니다. Horovod를 활용하면 적은량의 코드를 추가하여 손 쉽게 Distributed Training을 구현할 수 있습니다.
그렇다면 Tensorflow, Keras, Pytorch 모두 Distributed Training을 지원하는데 Horovod를 써야할까요?
개인적으로 Pytorch는 Horovod를 쓰지 않아도 괜찮다고 생각하지만 Tensorflow(Keras 포함)로 구현하신다면 Horovod를 쓰는 것을 추천합니다. 현재 (2019.12.19 기준) Tensorflow 2.0은 Distributed Training을 매우 한정적으로 지원합니다. 아래 표는 Tensorflow에서 지원하는 Distributed Training의 Strategy API들입니다. 대부분 실험적 지원 혹은 추 후 지원이고 Keras에서 지원 되는 MirroredStrategy는 Single Node에서의 Multi-GPU 사용만 가능합니다. (즉, GPU가 달린 Server 여러 대를 사용하는 Multi Node에서의 Distributed Training이 불가능합니다.)
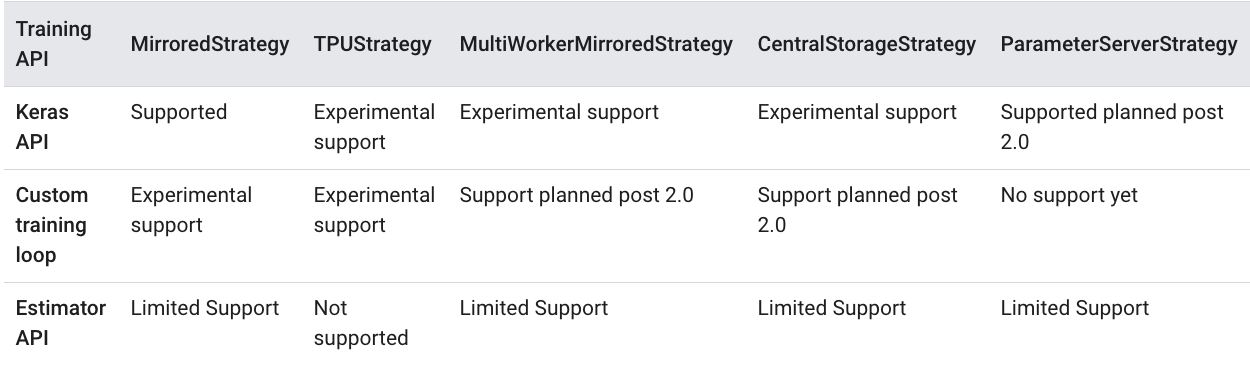
Horovod는 Tensorflow 2.0 뿐만 아니라 다양한 버전을 모두 지원합니다. 또한, Tensorflow 1.x 버전을 사용한다고 하더라도 Distributed Training 구현 방법, 동작 방식 등에 대한 설명이 Horovod에 더 잘되어 있고 코드 작성도 간편하여 Horovod 사용을 추천합니다.
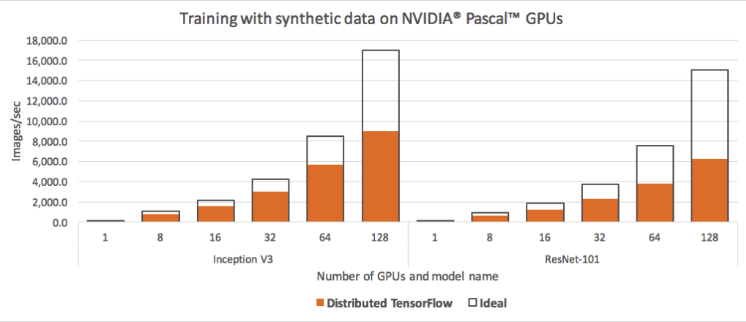
참고 : Tensorflow에서 위처럼 Strategy API를 쓰지 않고 이 곳 처럼 구현할 수도 있긴 합니다. 다만, 여기서는 Parameter Server 방식으로 구현하는데 이는 아래 그림 처럼 Horovod 보다 Distributed Training의 성능이 떨어지는 것을 알 수 있습니다.
Horovod의 Distributed Training 동작 방식
Horovod는 Bandwidth Optimal All-reduce Algorithm Paper를 기초로 하여 Bandwidth 사용이 최적화 된 Ring-allreduce 방식으로 동작합니다.
Ring-allreduce에 대해 설명하기 전에 Distributed Training의 전반적인 동작 방식에 대해 알아봅시다.
먼저, GPU 하나당 1개의 Worker Process가 학습하고자 하는 모델을 가지고 있고 일정량의 데이터를 읽어서 각자의 모델 학습을 위한 계산을 합니다. 좀 더 자세히 설명하면 각 Worker는 모델을 가지고 있고 학습 데이터를 읽어서 Forward, Backward를 통해 최종적으로 모델 Update를 위한 Gradients를 계산합니다. 이 후 Gradients를 Ring-allreduce 방식으로 서로 주고 받고 각자의 Worker는 모아진 Gradients들의 평균을 이용하여 모델을 Update 합니다. (처음 학습 시작 시 Master Worker가 모델 Parameter를 초기화 하고 모든 Worker에게 전달합니다. 위 설명 처럼 각 Worker는 iteration 마다 Gradient를 모두 모아서 Update 하므로 모든 Worker는 언제나 같은 Parameter를 갖습니다. 이를 Synchronous 방식이라고 하며 Asynchronous 방식도 있으나 설명은 생략합니다.)
그렇다면 Worker 간 Gradients를 주고 받는 Ring-allreduce는 어떻게 동작 할까요?
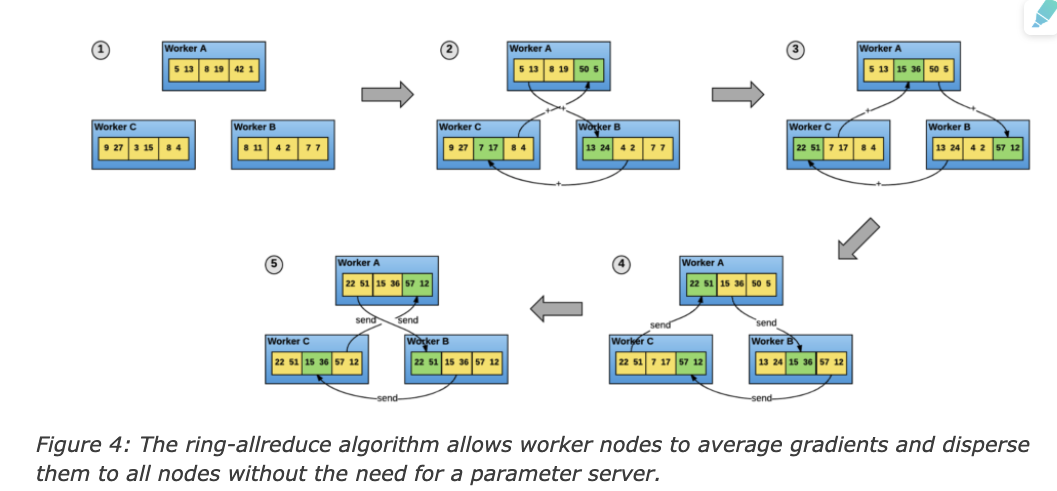
아래 그림은 3개의 Worker를 활용한 Ring-allreduce 예시입니다. 3개의 Worker는 Gradients들을 3조각으로 나누어 자신의 이웃 Worker에게 전달하는데 처음 2번(2,3)의 전송을 통해 각 Worker는 각자 1조각에 대해 모든 Worker의 Gradients를 가지게 됩니다.(3번을 보면 전송 시 2번에서 받은 Gradients 조각을 이웃 Worker에 전달 합니다. 3번에서 Worker A는 2번째 조각이 모든 Worker의 Gradients를 합친 조각입니다.) 마지막 2번(4,5)은 각 Worker가 자신이 갖고 있는 취합된 Gradients 조각을 이웃 Worker에게 전달해 주는 과정입니다.
따라서, N개의 Node가 있을 때 이웃 Node 간 2*(N-1)의 전송이 필요합니다.
서버 환경의 Distributed Training 성능 측정하기
Distributed Training을 직접 구현하면 얼마나 학습 속도가 빨라지는 지를 알고 싶을겁니다. 이를 위해 Horovod는 서버 환경에서의 Distributed Training 성능 측정을 위한 Benchmark 소스를 제공합니다. 임의로 생성한 이미지 데이터를 활용하여 Resnet과 같은 모델을 학습해보는 방식으로 사용하는 서버에서의 성능 측정을 해볼 수 있습니다.
이 글에서는 Tensorflow 1.13에서 실험을 해보도록 하겠습니다.
Benchmark를 돌려보기 위해서는 Horovod를 설치하는 작업이 필요합니다. 여러 대의 서버에서 실험할 경우 모든 서버에 동일한 환경을 설치해야하는데 이 작업을 줄이기 위해 Docker를 활용합니다. 아래 명령어로 먼저 제가 만들어 놓은 Docker Image를 다운받습니다.
>> docker pull yrok/horovod:0.18.2-tf1.13.2-py3.6-gpu
0.18.2-tf1.13.2-py3.6-gpu: Pulling from yrok/horovod
5b7339215d1d: Pull complete
....
....
Status: Downloaded newer image for yrok/horovod:0.18.2-tf1.13.2-py3.6-gpu
이제 다운 받은 Image를 활용하여 Container를 띄운 뒤 Benchmark 소스를 다운받아 실행 하면 됩니다. 먼저, 한 개의 서버에서 Multi-GPU 성능을 측정하는 경우를 설명한 뒤 여러 개의 서버에서의 성능 측정 방법을 설명하겠습니다.
한 개의 서버에서 성능 측정 시 아래 처럼 Container를 실행합니다.
# --gpus all (Host의 모든 gpu 사용)
>> docker run -it --gpus all yrok/horovod:0.18.2-tf1.13.2-py3.6-gpu
이 후 root 폴더에 이 곳의 Benchmark 소스를 다운 받습니다. (사용하는 Tensorflow Version에 해당하는 Branch의 소스를 다운받으면 됩니다.)
>> cd root
>> git clone -b cnn_tf_v1.13_compatible https://github.com/tensorflow/benchmarks.git
이제 다음의 명령어로 성능 측정이 가능합니다. (서버 1대에 2개의 gpu가 있을 경우의 명령어 입니다.)
'''
horovodrun 명령어의 option
-np 2 2개의 process 사용 (GPU 1개 당 1개의 Process가 사용됨)
-H localhost:2 (hostname과 해당 host의 process 수)
'''
>> horovodrun -np 2 -H localhost:2 python /root/benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py \
--model resnet101 \
--batch_size 64 \
--variable_update horovod
....
....
[1,0]<stdout>:1 images/sec: 149.7 +/- 0.0 (jitter = 0.0) 8.343
[1,1]<stdout>:1 images/sec: 149.7 +/- 0.0 (jitter = 0.0) 8.301
....
....
[1,1]<stdout>:----------------------------------------------------------------
[1,1]<stdout>:total images/sec: 300.87
[1,1]<stdout>:----------------------------------------------------------------
로그를 보면 [1,0], [1,1]은 각 프로세스에서 처리하는 초당 image 수를 나타내며 최종 로그 total images/sec: 300.87는 서버 환경에서의 Distributed Training 시의 초당 image 처리 속도를 나타냅니다.
여러 대의 서버에서 성능 측정 시 1개의 서버를 Master Node로 나머지 서버들은 Slave Node로 하여 동작합니다. Master Node는 처음에 horovodrun 명령어를 수행하는 서버로 자동으로 Slave Node에 Process를 실행하여 성능 측정 하는 역할을 합니다. 이 글에서는 서버 2대가 각각 gpu 2대를 가지고 있을 때를 예시로 설명합니다.
먼저, Slave Node들에서 Master Node의 요청을 받기 위해 위 처럼 Docker Image를 다운 받은 후 아래 명령어를 실행합니다.
'''
benchmark 소스를 다운 받고 ssh server를 실행한 상태로 master node의 요청을 기다림
--network host option을 주어 실행하는 container가 host의 네트워크 환경을 그대로 사용할 수 있도록 해주어야합니다.
'''
>> docker run --gpus all --network host yrok/horovod:0.18.2-tf1.13.2-py3.6-gpu bash -c "cd root; git clone -b cnn_tf_v1.13_compatible https://github.com/tensorflow/benchmarks.git; service ssh start; sleep infinity"
이제 Master Node에서 container를 실행합니다.
>> docker run -it --gpus all --network host yrok/horovod:0.18.2-tf1.13.2-py3.6-gpu
이 후 아래 처럼 명령어를 수행하면 여러 서버에서의 성능 측정이 가능합니다.
'''
-p 12345 (image에서 ssh default port를 12345로 설정하였음 )
-H localhost:2,xxx.xxx.xxx.xxx:2 (localhost와 slave server의 host 주소 및 process 수 설정)
'''
>> horovodrun -np 4 -p 12345 -H localhost:2,xxx.xxx.xxx.xxx:2 python /root/benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py \
--model resnet101 \
--batch_size 64 \
--variable_update horovod
BERT Fine Tuning을 Distributed Training으로 구현해보기
NLP에서 매우 큰 모델 중 하나인 BERT라는 모델을 Horovod로 Distirbuted Training 해보고자 합니다.
저는 이 블로그 글을 참고 했으며 구현된 소스는 이 곳에서 받을 수 있습니다. (해당 소스는 Google의 Official Code를 Lambda Labs라는 곳에서 수정한 코드 입니다.)
Horovod를 사용 하기 위해서는 이 곳의 설명과 같이 몇 줄의 코드만 추가하면됩니다. Tensorflow에서 Keras를 썼는지, Estimator를 썼는지 등에 따라 코드가 조금 다른데 이는 Example을 참고하면 됩니다.
BERT는 Estimator를 사용하여 구현되어 있습니다. 또한, TPU의 RunConfig를 사용하여 구현되어있으나 TPU가 없을 경우 자동으로 GPU로 동작하므로 걱정하지 않아도 됩니다. BERT를 Horovod로 Distributed Training 하도록 구현하기 위해서는 목적에 따른 학습 실행 코드(run_pretraining.py, run_classifier.py, run_squad.py)와 optimization.py를 수정해야합니다.
Horovod의 Distributed Training 동작 방식에서 설명했듯이 Horovod는 GPU 1개당 1개의 Process를 띄우며 Worker들은 batch size 만큼의 데이터에 대해 Forward, Backward를 통해 Gradients를 구하며 이를 Ring-allreduce 방식으로 주고 받은 후 모델을 Update합니다. 이를 위해 Horovod 코드를 일부 추가하는 것입니다.
먼저 (squad dataset에 대해 학습하는 경우) run_squad.py 코드를 수정 합니다.
# hvd code 1
import horovod.tensorflow as hvd
def main(_):
# hvd code 2 : Worker 간 Communication set up 등의 초기화 작업을 수행 합니다.
hvd.init()
# hvd code 3 : Worker 별로 모델 저장을 위한 Directory 다르게 설정합니다.
FLAGS.output_dir = FLAGS.output_dir if hvd.rank() == 0 else os.path.join(FLAGS.output_dir, str(hvd.rank()))
...
# hvd code 4 : 필요한 만큼 GPU의 메모리 할당, worker 1개 당 1개의 GPU 사용하도록 설정합니다.
hvd_config = tf.ConfigProto()
hvd_config.gpu_options.visible_device_list = str(hvd.local_rank())
# hvd code 5 : hvd_config를 session_config로 설정합니다.
run_config = tf.contrib.tpu.RunConfig(
session_config=hvd_config,
cluster=tpu_cluster_resolver,
master=FLAGS.master,
model_dir=FLAGS.output_dir,
save_checkpoints_steps=FLAGS.save_checkpoints_steps,
tpu_config=tf.contrib.tpu.TPUConfig(
iterations_per_loop=FLAGS.iterations_per_loop,
num_shards=FLAGS.num_tpu_cores,
per_host_input_for_training=is_per_host))
# hvd code 6 : hvd size(worker 수)를 고려하여 train step을 줄입니다.
# 예를 들어, 1 gpu에서 4 batch로 10 step 학습했다면 2 gpu에서는 8 batch로 학습되므로 5 step을 학습하도록 합니다.
num_train_steps = int(len(train_examples) / FLAGS.train_batch_size * FLAGS.num_train_epochs) // hvd.size()
num_warmup_steps = int(num_train_steps * FLAGS.warmup_proportion) // hvd.size()
# hvd code 7 : master worker가 처음에 모델 initialization 이후 다른 worker들에게 parameter를 전달 후 학습하도록 합니다.
# 처음 master worker에서 초기화한 parameter를 모든 Worker가 공유하고 학습이 진행 되므로 Worker 간 계속 같은 Parameter를 유지하게 됩니다.
hooks = [hvd.BroadcastGlobalVariablesHook(0)]
estimator.train(input_fn=train_input_fn, max_steps=num_train_steps,hooks=hooks)
다음으로 optimization.py를 수정합니다.
# hvd code 1
import horovod.tensorflow as hvd
def create_optimizer(loss, init_lr, num_train_steps, num_warmup_steps, use_tpu):
...
# hvd code 2 (optional} : learning rate를 worker수에 맞게 Scaling 합니다.
optimizer = AdamWeightDecayOptimizer(
learning_rate=learning_rate * hvd.size(),
weight_decay_rate=0.01,
beta_1=0.9,
beta_2=0.999,
epsilon=1e-6,
exclude_from_weight_decay=["LayerNorm", "layer_norm", "bias"])
# hvd code 3 : synchronous parameter update를 위해 optimizer를 wrapping 합니다.
optimizer=hvd.DistributedOptimizer(optimizer)
# hvd code 4 : 각 Node에서 gradient 계산 후 모델 Update 전에 이를 다른 Node들에게 전달하도록 합니다.
grads_and_vars=optimizer.compute_gradients(loss, tvars)
grads = [grad for grad,var in grads_and_vars]
tvars = [var for grad,var in grads_and_vars]
이제 서버 환경의 Distributed Training 성능 측정하기에서 처럼 Docker Image를 다운 받고 실행 후 학습하면 BERT를 Distributed Training할 수 있습니다.
Subscribe via RSS