[ALBERT 논문 Review] ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS
by y-rok
ALBERT 핵심 요약 (발표자료 PDF)
- [Challenge] BERT와 같은 Pre-trained language representation 모델은 일반적으로 모델의 크기가 커지면 성능이 향상됨. 하지만, 모델이 커짐에 따라 다음의 문제가 발생
- Memory Limitation - 모델의 크기가 메모리량에 비해 큰 경우 학습시 OOM(Out-Of Memory) 발생
- Training Time - 학습하는데 오랜 시간이 소요됨
- Memory Degradation - Layer의 수 혹은 Hidden size가 너무 커지면 모델 성능 감소
- [Contribution] BERT에 다음의 사항을 개선하여 모델의 크기는 줄이고 GLUE, SQuAD, RACE Task에 대해 더 높은 성능을 얻음
- Factorized embedding parameterization - Input Layer의 Parameter 수를 줄임 -> 모델 크기 줄임
- Cross-layer parameter sharing - Transformer의 각 Layer 간 같은 Parameter를 공유하여 사용 -> 모델 크기 줄임
- Sentence order prediction - BERT에서의 Next Sentence Prediction(NSP) 대신 두 문장 간 순서를 맞추는 방식으로 학습 (Masked LM 방식은 동일하게 활용) -> NSP 보다 SQUAD, MNLI, RACE task에서 성능 향상
Background
대용량 Unsupervised dataset으로 학습하는 Language Representation 모델은 ELMO, BERT 등이 있습니다. 이 중에서 BERT는 이번 포스트를 이해하기 위한 필수 내용입니다. 따라서, BERT를 잘 모르시는 분들이라면 다음 포스트들을 참고하시기 바랍니다.
BERT의 구조가 이해 됬다면 다음 사항을 기억하기 바랍니다. BERT는 모델의 크기에 따라 base와 large 모델이 있습니다. 말 그대로 large가 더 큰 모델이고 성능도 더 높습니다. 모델의 크기는 Layer 수와 각 Layer의 Hidden Unit의 수를 결정하는 Hidden Size에 의해 결정됩니다. 일반적으로 Language Representation 모델운 Layer 수, Hidden Size가 클 때 더 높은 성능을 보입니다. 그렇다면 무작정 Layer 수와 Hidden Size를 늘리면 좋을지, 모델 크기가 커짐에 따라 문제가 없는지 그리고 ALBERT는 BERT에서 어떠한 점을 개선하여 더 작은 모델 크기로 더 높은 성능을 달성했는지를 설명하도록 하겠습니다.
논문은 다음 순서로 설명하도록 하겠습니다.
1. [Challenge] Language Representation 모델의 크기가 클 때 발생하는 문제점
2. [Contribution] 모델의 크기는 줄이고 성능은 높이고!
1. [Challenge] Language Representation 모델의 크기가 클 때 발생하는 문제점
Pre-trained language representation 모델은 일반적으로 모델의 크기가 클 때 높은 성능을 얻는다고 알려져 있습니다. 이 때문에, 큰 모델로 먼저 학습하고 Knowledge Distillation 과 같은 방식으로 Model Compression을 통해 모델의 크기를 줄이곤 합니다.
그렇다면 모델을 무조건 크게 하여 학습 시키는게 최선의 방법일까요?
그렇지는 않습니다. 모델의 크기를 키웠을 때 메모리가 부족하다거나 학습 시간이 너무 오래 걸리는 문제가 있습니다. 또한, ALBERT에서는 일반적 사실과 달리 Language representation 모델도 너무 커지면 성능이 떨어지는 것을 실험적으로 보여줍니다. 이에 대해 하나 하나 설명하도록 하겠습니다.
1.1. Memory Limitation
모델이 클 경우 메모리량이 부족하여 OOM(Out-of Memory)이 발생할 수 있습니다. 메모리 128GB의 TPUv3을 여유롭게 사용할 수 있다면 문제가 없겠지만 12GB의 Titan X GPU를 사용한다고 해봅시다. 이 경우 BERT 학습 시 OOM이 발생하지 않을 때 Input Sequence Length에 따른 Maximum Batch Size가 아래와 같습니다.
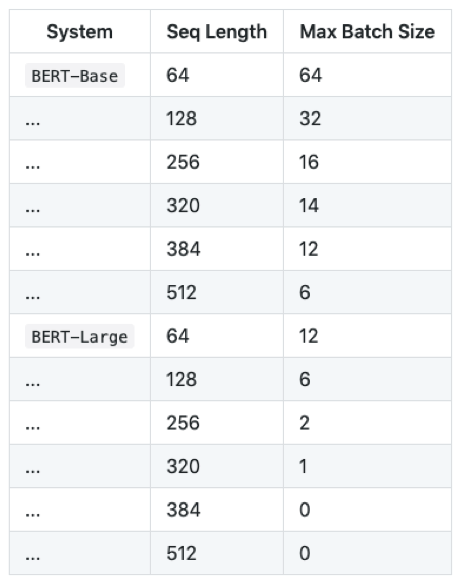
BERT Large의 경우 Input Sequence length가 384 이상이라면 Training은 물론 한 문장에 대해 Inference도 할 수 없습니다.
1.2. Training Time
BERT 모델은 학습하는데 상당한 계산량이 필요하기 떄문에 학습 시간도 오래 걸립니다. Google은 학습 시간을 줄이기 위해 여러장의 TPU를 활용하여 학습하였습니다. BERT base의 경우 16개의 TPU로 4일 정도 걸렸고, BERT large의 경우 64개의 TPU로 4일 정도 걸렸습니다.
그렇다면 GPU를 사용한다면 얼마나 오랜 시간이 걸릴 까요?
이 곳에 따르면, BERT base의 경우 16개의 V100 GPU 사용시 5일 이상, BERT large의 경우 64개의 V100 GPU 사용시 8일 이상이 소요 됩니다.
1.3. Model Degradation
ALBERT에서는 language representation 모델의 크기가 크다고 무조건 성능이 높아지지 않음을 실험적으로 보여줍니다. 아래의 그림을 보면 기존 BERT large 보다 더 큰 xlarge(large와 layer 수는 같지만 hidden size가 2배 큼)모델을 학습 시 오히려 성능이 떨어집니다. (논문에서 모델의 성능이 떨어진 이유는 설명하지 않고 실험적으로 결과만을 보여줍니다.)
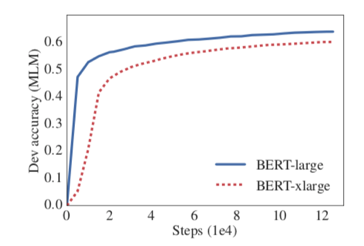
2. [Contribution] 모델의 크기는 줄이고 성능은 높이고!
ALBERT는 앞서 언급한 Challenge들을 극복 하기 위해 BERT에서 모델의 크기를 줄일 수 있는 방법과 Next Sentence Prediction 대신 다른 학습 방식을 제안합니다. 2.1, 2.2에서 모델의 크기를 줄이는 방법을 2.3에서 새로운 학습 방식에 대해 설명합니다.
2.1 Factorized embedding parameterization
BERT에서는 Input Token Embedding Size(E)와 Hidden Size(H)가 같습니다. (Hidden Size는 Transformer 각 layer의 input, output embedding size와 같습니다.) ALBERT에서는 E를 H보다 작게 설정하여 Parameter 수를 줄입니다. 그렇다면 E,H가 의미하는 바를 되짚어 보고 왜 ALBERT에서는 E를 H 보다 작게 설정하였는지 알아봅시다.
Input Token Embedding은 각 Token의 정보를 담고 있는 Vector를 생성합니다. 이에 반해, Transformer의 각 Layer에서의 Output은 해당 Token과 주변 Token들 간의 관계까지 반영한 Contextualized Representation입니다. 따라서, 담고 있는 정보량 자체가 다르기 때문에 E가 H 보다 비교적 작아도 될 것이라고 생각할 수 있습니다.
하지만 E가 H와 달라지면 첫 번째 Transformer layer 입력시 차원을 맞지 않습니다. 이는 Layer를 한개 더 추가하는 방식으로 쉽게 해결할 수 있습니다. V가 Vocabulary Size라면 기존 BERT는 VxH Matrix를 활용하여 Token Embedding을 했습니다. ALBERT에서는 VxE, ExH 2개의 Matrix를 연달아 곱하는 방식으로 H size의 Token Embedding을 만들어줍니다. BERT의 경우 V가 30,000으로 상당히 크고 이에 비해 E와 H는 작은 값이므로 ALBERT에서는 Parameter 수를 줄일 수 있습니다. (Embedding 과정을 2개의 Matrix로 나누어서 수행하므로 Factorized Embedding 이라고 합니다.)
논문에서는 실험을 통해 (H보다 작거나 같은)E의 크기 변화에 따른 성능을 보여줍니다. 빨간색 박스는 2.2 에서 설명할 Cross-layer parameter sharing 미적용 혹은 적용시 가장 높은 성능을 나타냅니다. E가 H 보다 작아도 크게 성능이 떨어지지 않는 것을 확인할 수 있습니다.
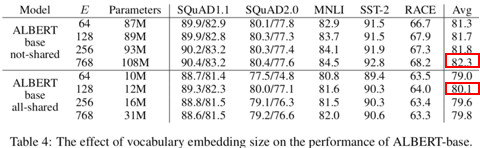
2.2 Cross-layer parameter sharing
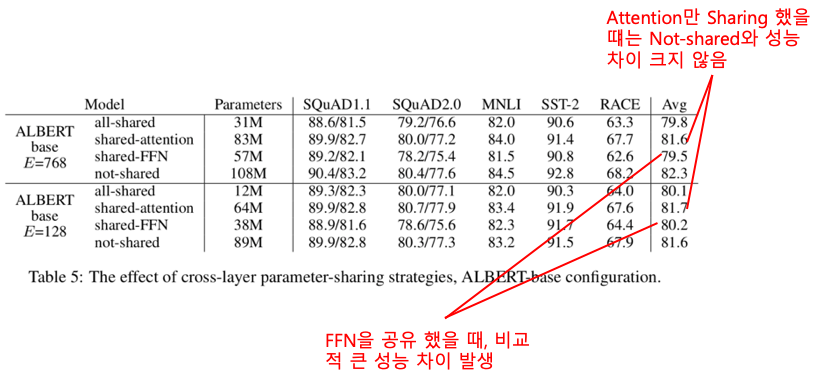
위의 표(Table 4)를 보다 보면 Factorized embedding parameterization 보다 Cross-layer parameter sharing 적용 시 모델의 크기가 훨씬 많이 줄어드는 것을 알 수 있습니다. Cross-layer parameter sharing은 말 그대로 Transformer layer 간 같은 Parameter를 공유하며 사용하는 것입니다.
이러한 아이디어는 ALBERT에서 처음 제안한 것은 아닙니다. Universal Transformer에서도 각 Layer는 Parameter를 공유합니다. 이는 아래 그림에서 처럼 Transformer의 각 Layer의 Output이 다시 Input으로 들어가는 형태로 Recursive Transformer라고도 할 수 있습니다.
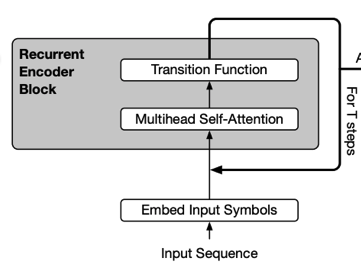
그렇다면 Layer 간 Parameter를 공유해도 성능이 떨어지지는 않을 까요?
아래 표에서 처럼 Self-Attention Layer만 공유 했을 때는 성능이 크게 떨어지지 않습니다. 다만, Feed Forward Network(FFN)은 공유 시 성능이 다소 떨어지는 것을 볼 수 있습니다. 논문에서는 실험 결과에 대한 해석은 하지 않고 있습니다. 왜 이러한 결과가 나왔는지는 고민해볼 필요가 있지만 Layer 간 Parameter를 공유 한다고 하더라도 크게 성능이 떨어지지 않는 다는 결과는 큰 의미가 있습니다. 따라서, ALBERT는 BERT와 같은 layer 수, Hidden Size일지라도 모델의 크기가 훨씬 작습니다.
2.3 Sentence order prediction
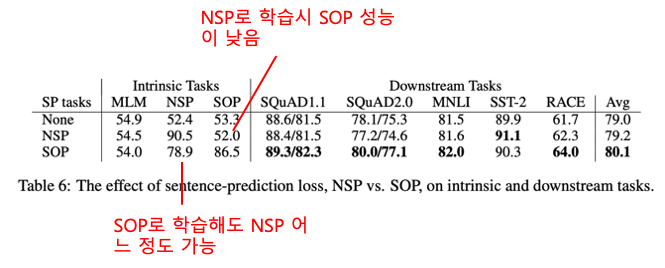
이 논문에서는 Next Sentence Prediction(NSP) 보다 나은 학습 방식인 Sentence order prediction SOP)을 제안합니다. NSP는 두번 째 문장이 첫 문장의 다음 문장인지를 맞추는데 학습 데이터 구성 시 두 번째 문장은 실제 문장(positive example) 혹은 임의로 뽑은 문장(negative example)이 됩니다. 하지만, 임의로 뽑은 문장은 첫 문장과 완전히 다른 Topic의 문장일 확률이 높으므로 문장 간 연관 관계를 학습한다기 보다는 두 문장이 같은 Topic에 대해 말하는지를 판단하는 Topic Prediction에 가깝습니다. 이에 반해 SOP의 학습 데이터는 실제 연속인 두 문장(Positive Example)과 두 문장의 순서를 앞뒤로 바꾼 것(Negative Example)으로 구성되고 문장의 순서가 옳은지 여부를 예측하는 방식으로 학습합니다. 따라서, SOP로 학습 시 두 문장의 연관 관계를 보다 잘 학습할 것이라고 기대할 수 있습니다.
아래 표는 ALBERT에 NSP, SOP 학습 시 성능을 비교합니다. SOP로 학습 시 NSP는 어느 정도 가능하지만 NSP는 문장 간 관계를 잘 학습하지 못하기 때문에 SOP 성능이 매우 낮은 것을 볼 수 있습니다. 또한, 두 문장 이상을 입력으로 넣어 수행하는 SQuAD, MNLI,RACE 등의 Task에서 SOP 적용 시 성능이 더 높다는걸 알 수 있습니다.
3. [Experiment] 모델 성능 평가
논문에서는 다음과 같이 ALBERT를 학습하여 성능을 평가 합니다.
- Batch size = 4096
- 125,000 Steps 학습
- 모델의 크기에 따라 TPUv3를 64~1024 chips 활용
- Wiki, Book Corpus - 16GB 학습 데이터
- ALBERT는 Layer 간 모든 Parameter 공유
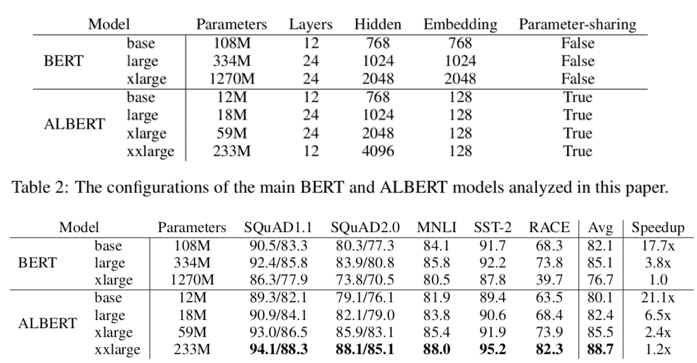
아래 그림의 성능 결과를 보면 앞서 언급했던 3가지 Challenge가 해소된 것을 확인할 수 있습니다.
Memory Limitation
ALBERT느 BERT와 같은 Layer 수, Hidden size에서 모델의 크기가 훨씬 작습니다. 따라서, Memory 사용량을 훨씬 줄일 수 있습니다. (ex) BERT large - 334mb, ALBERT large - 18mb)
Training Time
마찬가지로 layer 수, Hidden size가 같을 때 ALBERT는 BERT 보다 학습 속도가 훨씬 빠릅니다. 다만, 계산량이 얼마나 적어지고 등의 명확한 이유는 아직 제가 정확히 파악하지 못해 좀 더 공부하고 글을 업데이트 하겠습니다. (ex) ALBERT xlarge는 BERT xlarge 보다 학습 속도가 2배 빠름)
(논문 내용 : Because of less communication and fewer computations, ALBERT models have higher data throughput compared to their corresponding BERT models.)
Model Degradation
BERT는 large에서 xlarge로 커질 경우 오히려 성능이 떨어집니다. 하지만, ALBERT의 경우 xxlarge가 xlarge 보다 그리고 xlarge가 large 보다 성능이 높은 성능을 보입니다. 물론, ALBERT도 계속 해서 Hidden size와 layer 수를 늘린다면 성능이 떨어질 것입니다. (논문에 따르면 Hidden size가 6144개일 때,4096개 일 때 보다 성능이 떨어집니다.) 하지만, ALBERT는 BERT xlarge 보다도 더 큰 xxlarge 모델도 Model degradation이 발생하지 않으므로 다양한 Downstream task에 더 높은 성능을 얻을 수 있었습니다.
(논문에 추가 데이터로 학습, Dropout 활용 여부 등 다양한 실험 결과가 더 있으니 참고 바랍니다.)
정리하면 ALBERT는 BERT에서 모델의 크기를 줄일 수 있고 Model Degradation이 BERT xlarge 보다 더 큰 xxlarge 모델에서도 발생하지 않기 때문에 더 높은 성능을 얻을 수 있었습니다. 모델 성능이 향상된 것도 중요하지만 모델의 크기가 현저히 줄어 Memory Limitation 문제를 해결한 것도 큰 Contribution인 것 같습니다.
Subscribe via RSS